Upgrade Aurora PostgreSQL with Minimal Downtime using AWS DMS
Upgrading or Migrating a database is very challenging tasks, we have to take care of ’N’ number of things and lot of factors affect the upgradation of the database to a new version but it is always a best practices to use the updated version, before you upgrade your database cluster to a newer version it is also important to test the upgrade in your Dev/Test/Load Environments and then plan the upgrade in PROD Environment.
There are different ways in which you can upgrade your DB Cluster Version
- In-Place Upgrade: — In-Place Upgrade time totally depends on the size of the database, if your database size is small you can use In-Place Upgrade. Remember one thing that during In-Place Upgrade you can not use your database cluster, your application can not connect to your database
- Use some third party tool
- AWS Database Migration Service
For using AWS Database Migration Service you need to create new RDS Cluster with the newer version and then you Migrate your data from old cluster (Source) to new cluster (Target) using DMS
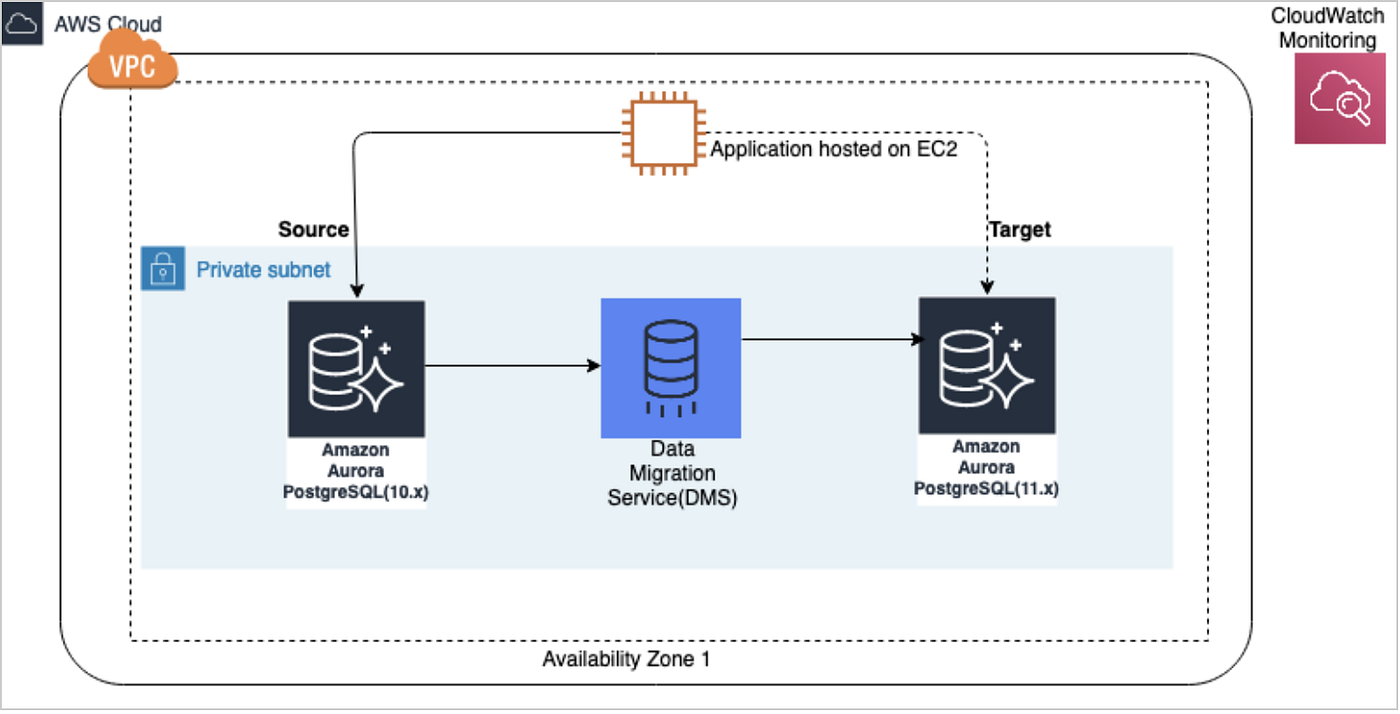
Prerequisite for using AWS DMS:
- Source Cluster
- Target Cluster with new Version
- Replication Instance
- Source and Target Endpoints configured in DMS and connection with source and target database should be successful
There are 3 different ways in which you can use AWS DMS
- Full Load : — In this approach you stop writes on your source database cluster, so that data consistency is maintained, you create DMS task and migrate the data to target cluster and point your application to new cluster endpoint. You can improve the DMS Tasks performance by adjusting some parameters and doing some configuration to reduce the migration time (We will discuss about improving DMS tasks performance in this blog)
- Full Load with Ongoing Changes : — I will explain this approach in this blog post
- Replicate Ongoing Changes only
In this blog post I will take a hypothetical example and will explain to you how can we use AWS DMS to Upgrade your database cluster version. In this blog post my source DB version is 10.11 and target DB version is 12.6
Consider that we have a sample_db which has 10 tables , Every table has id column which is primary key and the value is generated by sequence in PostgreSQL.
We will collect some statistics so that we can plan our DMS Tasks accordingly.
- Get total size of the DB
select datname, pg_size_pretty(pg_database_size(datname))
from pg_database order by pg_database_size(datname) desc limit 10;The above query will give us total size of all the database in the cluster
2. Get the size of individual tables in sample_db
SELECT table_name,
pg_size_pretty(pg_relation_size(quote_ident(table_name))),
FROM
information_schema.tables
WHERE
table_schema = 'public'
ORDER BY
pg_total_relation_size(quote_ident(table_name)) DESC;# Output table_name | pg_size_pretty |
---------------------------------------+----------------+-----------
table1 | 850 GB |
table2 | 200 GB |
table3 | 3200 MB |
table4 | 1200 MB |
table5 | 5600 MB |
table6 | 4200 MB |
tabel7 | 3167 MB |
table8 | 250 MB |
table9 | 81 MB |
table10 | 144 MB |
3. Get the count of number of records from every table
select count(1) from <table_name>;# consider we have count of records as followstable1 -> 345000000
table2 -> 87000000
table3 -> 56300000
table4 -> 36000000
table5 -> 23400000
table6 -> 8970000
table7 -> 7890000
table8 -> 65400
table9 -> 43100
table10 -> 1520
Now we have all the required information to plan our database upgrade/migration activity. We will use above statistics to design our DMS tasks and we will leverage features provided by AWS DMS to Migrate the data efficiently into target database.
Let’s Get Started
Step I :- Create new Cluster Parameter Group for source RDS
- Create a new Parameter Group for Postgres version 10
- Set
rds.logical_replicationto1andwal_sender_timeoutto0(Logical Replication should be enabled for capturing CDC) - Set
rds.log_retention_periodto7200(We will store it for 5 days) - Set
max_replication_slotsto20(This parameter value depends on Number of DMS tasks we create, generally 1 DMS task uses 1 Replication Slot) - Edit your cluster configuration to point to new parameter group
- Reboot the Reader and Writer Instance to apply a new cluster parameter group. (You need to reboot the reader and writer instance because some parameters are static parameters, so it requires reboot to take effect)
Step II :- Create new Cluster Parameter Group for target RDS. We will do some changes later in target cluster parameter group once we are done with schema dump and restore.
Note: — Make sure you update your target cluster configuration to use new cluster parameter group.
Step III :- Schema dump and restore from source to target
- Create a new folder
mkdir db_schema2. Run the following command to take schema dump
pg_dump -h <source_endpoint> -U <source_user> -d <source_db> --schema-only --verbose --jobs 8 -Fd -f /home/ec2-user/db_schema3. Create Roles/Users in the Target cluster if you are using it in source cluster
4. Restore Schema on Target
pg_restore -h <target_endpoint> -U <target_user> -d <target_db> --verbose --jobs 8 -Fd /home/ec2-user/db_schemaStep IV :- Disable the triggers in target Database.
In PostgreSQL Foreign Key Constraints, Constraints etc are handled by Triggers, we need to disable those triggers during the migration process.
- Set
session_replication_roletoreplica(set this in target cluster parameter group)
Step V :- Create AWS DMS Tasks
Now that we have all the required information and we have collected the database statics also, it is time to create DMS Tasks which will be responsible for Migrating our data into target database.
After analysing statistics we can say that we have huge number of records to migrate it is advisable to create 1 DMS Tasks for every table In this way we will be reducing the risk if something goes wrong during the migration process and it will have impact only on that specific table.
So we will create 10 different tasks 1 for each table.
Now I will cover some scenarios to cover the features provided by AWS DMS and based on that we will create our tasks.
- Table1 :- Consider that we want to migrate records which has value of
idcolumn greater then equal to155000000into target database. In this case we will usefiltersfeature of DMS. So total number of records to migrate will be345000000–155000000 = 190000000
Let’s see how to configure task.
a. Go to Database Migration Task page and click on Create task
b. Give a unique name to your task, Select your replication instance, Select your Source and Target Endpoints.
c. In the Migration Type Select Migrate Existing Data and Replicate Ongoing Changes
d. In the target table preparation mode select Truncate It will give you a warning of possible data loss (Truncate mode is useful when something goes wrong during the Full Load Operation, because when you restart the task it will copy all the data from start and if it finds the existing record in target it will truncate that records and it will copy that row again, so it reduces the chances of data loss).
Note: — If something goes wrong during the full load operation, it is always recommended to Restart the task instead of Resuming the task and the table preparation mode should be Truncate. Once the CDC Phase starts the table preparation mode is not considered by DMS and you can Resume the task if it is in CDC mode, because it uses the checkpoints to migrate the data into target database.

e. You can enable CloudWatch Logs with default settings (Optional)
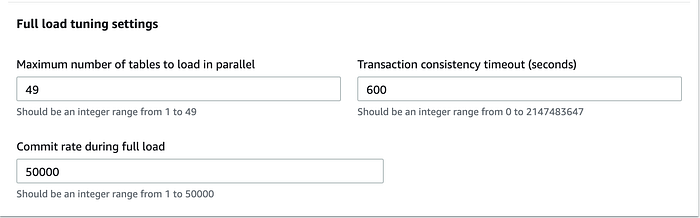
f. In the Advance task settings set the Full Load Tuning Settings
- Set
Maximum number of tables to load in parallelto49(Actually it is number of threads, the max value can be upto 49 only, we are telling DMS to do full load using 49 threads) - Set
Commit rate during full loadto50000
g. scroll down to table mappings Now this is very import, In this we will configure source filter and parallel load for table. Now we know that we have to migrate 190000000 number of rows what we will do is we will divide this number into 45 parts and we will create segments for parallel load. (you can divide with any number but remember we can run 49 threads in parallel, 1 segment will be 1 thread, So if you divide number with more then 49 threads say 60 so it will load 49 threads in parallel and once the thread is free it will load data from next segment).
Now, 190000000/45 = 4222222.22222 so 1st segment will be 155000000+4220000 = 159220000. Similarly 2nd segment will be 159220000+4220000 = 163440000 , 3rd segment will be 163440000+4220000 = 167660000 and so on we will create 45 segments. So our values of segments will be 159220000, 163440000, 167660000, ....
Your json should look something like this:
{
"rules": [
{
"rule-type": "selection",
"rule-id": "1",
"rule-name": "1",
"object-locator": {
"schema-name": "public",
"table-name": "table1"
},
"rule-action": "include",
"filters": [
{
"filter-type": "source",
"column-name": "id",
"filter-conditions": [
{
"filter-operator": "gte",
"value": "155000000"
}
]
}
]
},
{
"rule-type": "table-settings",
"rule-id": "2",
"rule-name": "2",
"object-locator": {
"schema-name": "public",
"table-name": "table1"
},
"parallel-load": {
"type": "ranges",
"columns": ["id"],
"boundaries": [
["159220000"],
["163440000"],
["167660000"],
.
.
.
.
.
["340780000"]
]
}
}
]
}In above task we have added source as filter-type which will migrate the records from value greater then or equal to 155000000 from the source. We have added parallel-load and created 49 boundaries.
These 45 boundaries thus identify the following 46 table segments to load in parallel:
Segment 1: Rows with id less than or equal to 159220000 but not less then 155000000 because we have source filter.
Segment 2: Rows other than Segment 1 with id less than or equal to 163440000
……….
Segment 46: All remaining rows other than Segment 1, Segment 2, Segment 3, ……, Segment 45
h. Scroll down till Migration task startup configuration and select Manually later for Start migration task (once you save the task it is recommended to verify all the settings of the tasks).

i. Click on Create task button
We have successfully created task for table 1 verify everything and lets move to task creation for table2.
2. Table2 :- In table2 we have to migrate all the records, but 1 thing to note is we have to migrate 87000000 number of rows. We can use parallel-load feature of DMS as we did for 1st task and we will create 45 segments for this. Follow the same till point 'f’ of task 1 and for table mappings lets do calculations for segments.
Now 87000000/45 = 1933333.33333 so each segment will have ~ 1930000 number of rows. So, first segment will be 1930000 , Similarly 2nd segment will be 1930000+1930000 = 3860000 , Third segment will be 3860000+1930000 = 5790000 and so on create 45 segment. So our values of segments will be 1930000, 3860000, 5790000, ....., 85070000
Your json should look something like this:
{
"rules": [
{
"rule-type": "selection",
"rule-id": "1",
"rule-name": "1",
"object-locator": {
"schema-name": "public",
"table-name": "table2"
},
"rule-action": "include",
"filters": []
},
{
"rule-type": "table-settings",
"rule-id": "2",
"rule-name": "2",
"object-locator": {
"schema-name": "public",
"table-name": "table2"
},
"parallel-load": {
"type": "ranges",
"columns": ["id"],
"boundaries": [
["1930000"],
["3860000"],
["5790000"],
.
.
.
.
.
["85070000"]
]
}
}
]
}These 45 boundaries thus identify the following 46 table segments to load in parallel:
Segment 1: Rows with id less than or equal to 1930000
Segment 2: Rows other than Segment 1 with id less than or equal to 3860000
……….
Segment 46: All remaining rows other than Segment 1, Segment 2, Segment 3, ……, Segment 45
h. Scroll down till Migration task startup configuration and select Manually later for Start migration task (once you save the task it is recommended to verify all the settings of the tasks).
i. Click on Create task button
Similarly create task definitions for Table3, Table4, Table5, Table6 and Table7. Calculate the segment values as we did for Table1 and Table2 and all other settings will remain same for the tasks.
For Table8, Table9 and Table10 you can either create separate tasks for each table or you can have 1 Task definition for all 3 tables. There is no need of dividing this tables into segments because number of records are less
If you are planning to have 1 task definition for last 3 tables then it will look something like this:
{
"rules": [
{
"rule-type": "selection",
"rule-id": "1",
"rule-name": "1",
"object-locator": {
"schema-name": "public",
"table-name": "table8"
},
"rule-action": "include",
"filters": []
},
{
"rule-type": "selection",
"rule-id": "2",
"rule-name": "2",
"object-locator": {
"schema-name": "public",
"table-name": "table9"
},
"rule-action": "include",
"filters": []
},
{
"rule-type": "selection",
"rule-id": "3",
"rule-name": "3",
"object-locator": {
"schema-name": "public",
"table-name": "table10"
},
"rule-action": "include",
"filters": []
}
]
}Congratulations! 🥳 Now we are ready to start the migration tasks, verify the settings of all the DMS tasks and start the DMS Tasks one by one. Select the DMS task click on Actions and then click on Restart/Resume button.
If you face any issues during the full load operation just stop the DMS task, resolve the error and now when you click on Restart/Resume button it will ask you 2 options Restart or Resume If your table preparation mode is truncate I recommend you to Restart the task.
During the Migration Process you can actually view the number of records migrated from source db to target db and elapsed time. you can view all this statistics by click on DMS task and then go to Table Statistics tab. Once the CDC Phase starts it will also show number of records inserted or updated on particular table.
Once the Full Load is completed the status of DMS task will change to Full Load Complete, Replication on going which means the CDC Phase has started, now based on the business requirements you have to plan a downtime window to switch to new database endpoint.
Switch DB Connection Endpoint
Once the stats of DMS task changes to Full Load Complete, Replication on going go the metrics tab of DMS task and select CDC in the filter. It will show you N number of different metrics but out of them 2 metric are important for us to make sure that there is no latency between source and target database those 2 metric names are CDCLatencySource (LatencySource) and CDCLatencyTarget (LatencyTarget).
Once you plan a downtime window perform the following :
- Stop the write to your source database by stopping the application/s which writes to that database
- Wait for CDCLatencySource (LatencySource) and CDCLatencyTarget (LatencyTarget) Metric values to come to 0, once value of metric are 0 it means that our data is in sync between source and target database
- Stop all the DMS Tasks
- (Optional) You can do a data validation by running the following query in source and target database
select max(id) from table_name;5. If you are using sequences then you need to manually reset the value of every sequence in target database. To reset the sequences you can use one of the following method:
# Method 1select max(id) from table_name;
ALTER SEQUENCE <SEQ_NAME> RESTART WITH <NEW_MAX_VAL>;
select nextval('<SEQ_NAME>');
select currval('<SEQ_NAME>');--------------OR------------------# Method 2SELECT setval('<SEQ_NAME>', (SELECT MAX(id) FROM table_name));You can be ready with the queries before the downtime window if you are using method 2 to reset the sequence
6. Go to Target Cluster Parameter Group and set session_replication_role to origin It will enable all the triggers. (Very Important step)
7. Update your configuration files with the new RDS PostgreSQL Database cluster Endpoint and restart your services.
Congratulations!!! 🥳
You have successfully Upgraded/Migrated your Aurora PostgreSQL Cluster with minimal downtime.
Thank You!
Reference:
- https://docs.aws.amazon.com/dms/latest/userguide/CHAP_Source.PostgreSQL.html
- https://docs.aws.amazon.com/dms/latest/userguide/CHAP_Target.PostgreSQL.html
- https://docs.aws.amazon.com/dms/latest/userguide/CHAP_ReplicationInstance.Types.html
- https://docs.aws.amazon.com/dms/latest/userguide/CHAP_Tasks.CustomizingTasks.Filters.html
- https://docs.aws.amazon.com/dms/latest/userguide/CHAP_Tasks.CustomizingTasks.TableMapping.SelectionTransformation.Tablesettings.html
- https://aws.amazon.com/premiumsupport/knowledge-center/dms-error-null-value-column/
